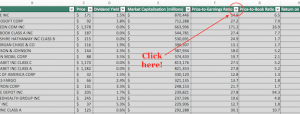
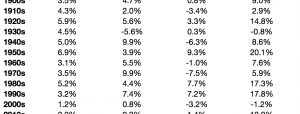
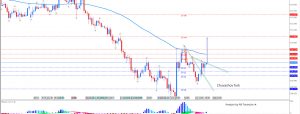
As we move further into 2017, economic statistics will be subject to their annual benchmark revisions. High-frequency data such as any accounts published on or about a single month is estimated using incomplete data. It’s just the nature of the process. Over time, more comprehensive survey results, as well as upgrades to statistical processes, make it necessary for these kinds of revisions.
There is, obviously, great value in having even incomplete data estimates published in as close to real time as can be possible right now. Most of the time there aren’t major revisions to a data set because by and large growth is to some degree predictable. That is the essence of trend-cycle subjectivity, as government statisticians in the past had been able to more easily determine the trajectory for whatever economic data and use it to further construct the trend-line for measured monthly variation.
The problem, equally obvious, is for any period where the assumed trend becomes obsolete. In the past, that had typically meant a recession, for any statistical series always has difficulty with inflection due to the basic premise of using the recent past to try to measure the near future. Such a short-term discrepancy was something we could all live with because if whatever piece of information didn’t exactly tell us when the inflection was reached we would anyway soon enough be able to easily infer it by common sense at least.
This “recovery” period was at first modeled by trend-cycle analysis as a recovery. That was evident across a range of statistics but to the most visible extreme with Industrial Production. The Fed’s subjective assumptions about the state of US industry produced self-reinforcing guidance about that agency’s forward assumptions of the state of the economy (IP was growing steadily, therefore QE must be working). The data issue, then, is revealed where recovery, at least one consistent with past recoveries, doesn’t occur. If that was to be the case, then even the most robust statistics like IP with its almost 100 years of data would encounter serious and significant problems accurately depicting what was really going on – meaning that the data series reflected more subjectivity than actual results.